Clients often ask me what they can do to ensure the highest level of quality in Machine Translation of pages and documents. This blog post applies particularly to users of PointFire Translator, but since the translation technology that we use is similar to that of other products that follow the leading edge of machine translation technology, most of the advice below applies to other machine translation scenarios. If you are using the machine translation of PointFire on premise or SharePoint on premise, that is much older technology, and the advice would be a bit different.
The first thing that you need to do is determine your tolerance for errors in different types of documents and the time and money you are willing to spend to correct the errors. Not all documents need to be translated with the same level of quality. Some of them are fine if you get the gist, while others must be very faithful to the original.
A good human translator will charge about 10-50 cents per word depending on the languages and the type of text. Azure Translator text API will charge about 0.02 cents per word, Azure Translator document API will charge about 0.04 cents and Azure Custom translator will charge 0.1 cents. These are round figures, but the cost savings from machine translation is considerable.
How accurate are the translations from machine translation? That is a complex subject, but in the past decade we have gone from statistical machine translation which was still barely better than gibberish except for languages from the same family, to the current situation where translation for many language pairs including English to Chinese and back, has reached what is called ”human parity”, to the next generation of machine translation based on Z-code MoE models (more on that below), with dramatic improvements in many language pairs.
What does "human parity" mean?
Let us stand back and try to understand what the term “human parity” means and what it doesn’t.
First, the humans in question are not professional translators. Professional human translators are still better. The tests that justified the use of that term came from an annual competition where both humans and machines translated sentences from news stories. Journalistic style is relatively simple, and the machines had trained on other news stories, so that makes it easier. The two sets of translations, human and machine, were then scored independently for quality. Microsoft Azure Translator obtained as good a score as the average human. But remember, the humans in this comparison were probably bilingual computer science students, as were the evaluators. If the testing had been done with professional translators doing the translation and doing the rating, it would not have been a tie, as other studies have shown. “Human parity” is a good benchmark, but it is far from perfection. There are still errors.
What are these human parity errors and what can we do about them?
Different language pairs will have different types of errors. Again, depending on the types of errors you are getting and how badly you need to correct them, there are different things that you can do. Take negation errors for example. These are easily noticeable by users. A sentence that contains a negative in the source language may be incorrectly missing the negation in the target language, or vice-versa, or may have incorrect scoping: does the not/nicht/kein apply to one adjective, to the whole clause, or to the verb? Some languages handle negation differently, and it is not necessarily clear to the translation engine what is being negated. It is a particular problem between English and either Russian, Lithuanian, or German. Part of the reason is that training sets used to create and tune translation engines don't contain a lot of negation.
Negation is only one category of errors among many others, but a very noticeable one. Linguistic and statistical measures of quality will say the translation is very, very close, it’s only off by one word, but the client will say not it’s not, it’s as wrong as it could be, it’s the opposite. It is a very simple error to correct, it requires very little editing time to change it. Humans and machines have very different evaluation criteria.
Four things you can do to improve translation quality in general
Four things you can do to improve translation quality in general
- Implement a post-editing step that looks particularly for certain kinds of common translation errors before publishing
- Switch to Azure Custom Translator and train it on a corpus of your own documents and phrases so that it learns your vocabulary and your style
- Participate in the by-invitation pilot of the Z-Code MoE translation engine
- Change the style guide of source documents so that they are written in a way that is easier to translate
1. Post editing
Post editing is the simplest and most robust solution. It means making changes to the translated page or document. It should be implemented whether or not you implement some of the other solutions. Machine translation is not perfect, so limited post-editing is good practice. It is still significantly cheaper than professional translation or editing and may be cheaper than Azure Custom Translator. PointFire Translator by default saves all documents, pages, and items as drafts, and someone should revise that draft before it is published. This advice is not what most people want to hear, they want a technology solution because they don’t have the in-house expertise to translate, and would like the technology to solve the problem without involving them. Sorry.
Who should do this?
The obvious answer may not be the best one. “We have someone in the office who speaks both languages”. No matter how clever they are, efficiently editing documents in their other language may not be in their skill set. And you have to make sure that someone’s ethnicity or cultural background does not mean that they get extra tasks that do not contribute to their career progression or career goals.
What is this “limited editing” that I mentioned? That is actually very challenging even for professional editors and translators. You want to limit the time that is spent in this editing step, otherwise you will end up spending more on post-editing than you would have for professional translators. Remember, professional translators have access to machine translation too. Today’s translators are already only charging you for machine translation plus the cost of post-editing, and they are very good and quick at doing this. They have glossaries, translation memory databases, and previous translations at their fingertips and they do this all day. The cost advantage that you have over them comes from the fact that they’re perfectionists and you’re not.
Limited post-editing means you correct some errors that are show stoppers and easy to correct, like negation errors, and let other errors slide. You find poor phrasing, not quite the right word, or errors in agreement between the noun and the adjective? These are errors that do not require reading the original text in a different language in order to correct, and everyone reading it knows what the author meant to say. And those errors are more time-consuming to correct. I know it’s hard to see an error on a page that you are editing and leave it there, and not everyone agrees with this advice, but this is how you control costs. Given the current quality of machine translation, for most documents you will not even hit the edit button, you will click on publish if you can resist the temptation to fiddle with the text until it’s perfect. Different types of documents require different edit rules. If the text is describing a procedure that must be exact, spend more time ensuring that it is exact. It’s like a food processing assembly line. There are some acceptable defects, but also some that cannot be tolerated no matter the cost.
As we will see below, certain errors are difficult to prevent by other methods. Post editing is the best way to correct them, but if too much post-editing is required or too many errors are missed, professional translators may be a safer or less costly alternative.
2. Custom Translator
While Azure Translator uses the same translation engine for everyone, Azure Custom Translator is an alternative engine that you can re-train on your documents and vocabulary. It can increase translation accuracy by a few points, particularly for specialized domains. You’re in the automotive industry? Tell Custom Translator and your score will already improve over the default engine.
Unfortunately, re-training a translation model, the main component of the translation engine, is not very simple and it requires some knowledge of linguistics and statistics, plus a lot of data and data cleaning, to get the advantage of having your own model. The new preview interface of Azure Custom Translator is a big improvement, but it still needs some work. I may blog more in the future about how to use it, but here is a brief introduction.
First you need to have at least 10,000 professionally translated sentences or terms, in a supported format and following the naming conventions. This is the learning set. You can upload parallel documents in both languages, and it has some tools to help you align the sentences, but it’s not as good as you’d think and you have to revise carefully. If an extra line is inserted, every sentence after that will be mis-aligned. You also have to remove the sentences that are not quite the same. Translators often split or combine sentences when they translate, it may be more natural sounding that way, but it will confuse the translation engine training, best to remove those. Similarly, some translations, although correct, are not a good example for a machine to train on. For example, if the text is talking about pangrams, sentences that use all 26 letters, “the quick brown fox jumped over the lazy dog” can be translated to “Portez ce vieux whisky au juge blond qui fume” (Carry this old whiskey to the blonde judge who smokes). While it’s correct in this context, having a model learn from this translation would probably interfere with the model’s ability to translate other text about canids. Training sets have to curated to be most effective. How about idioms, expressions that do not translate literally? Those are good, training sets should include them so that it will know later how to translate those in a way that is not literal.
Besides those 10,000 sentence pairs, you will also need a testing set and a tuning set. To simplify the process a bit, neural network models train on a training set, but you also need a set of sentences to test on. If you over-train a neural network translation model, it will become very good with the sentences it has seen, but at some point it becomes worse at the sentences that it hasn’t seen. It is memorizing the training sentences, but not generalizing. You have to stop the training when it gets to the highest quality score, and before it gets worse. The measure of quality that it is optimizing is called the BLEU score. Again simplifying a bit, the BLEU score looks at the translation that the model produced and compares it to the translation that a professional translator provided. The score is a purely numerical comparison. For each sequence of 4 words in your translation, does that sequence of 4 words appear in the reference professional translation? How about for sequences of 3, 2, or 1 words? The score has other factors as well, but that is the essential.
A couple of notes about the BLEU score:
- Professional translators don’t get perfect marks because one translator can phrase things differently from other translators. They will get maybe 50 out of 100.
- BLEU score is not good at punishing long-range errors, things that are more than 4 words apart like negation for instance
- It doesn’t care about meaning or synonyms. If you use the word “large” and the translator used the word “big”, you get the same score as if you had used “small” or even “but” or “blarg”
For better or for worse that score is what Azure Custom Translator is trying to maximize. It starts out with a good general model, and then it modifies it a using the training data that you provide. The “tuning set” of training data is especially crucial. It has to be very representative of the translations that you will carry out later, and a lot of the quality of the model depends on having the correct distribution of and range of documents in this set.
How much more translation accuracy you can get by using Custom Translator depends on the language pair and on the type of text. For example, English-German already has very high translation quality without re-training, so the improvement may be smaller than other languages. Version 1 of Custom Translator improved the accuracy of English-German over the normal Azur Translator by a few points of BLEU score, much more in the automotive field with a medium number of documents. “Medium” in this case means 50-100 thousand professionally translated sentences.
You can find more details here
Version 2 of the Custom Translator, which includes “human parity” models that PointFire uses, improved even further particularly for languages where Version 1 had not performed as well like Korean and Hindi, although less so for languages where it was already good like German.
More information here
Depending on the language and the field, particularly how your specialized vocabulary differs from the vocabulary that Microsoft used in its training, typically government documents crawled from the web, you can get small to significant improvements in translation quality by training your own model in Azure Custom Translator. However, it requires significant investment in time and resources to set up, and Microsoft charges 4-5 times what it charges for the regular translation engine. It is not for everyone.
3. Z-code MoE models
Z-code is part of Microsoft’s larger ambitious “XYZ-code” initiative. It takes advantage of new technology for massive, massive neural networks of a scale barely envisioned a few years ago, billions or even hundreds of billions of parameters, made possible with the Microsoft DeepSpeed library https://www.deepspeed.ai/. It’s thousands of times bigger than current translation models. Rather than separately training individual models for English-French, English-Hungarian, English-Chinese, etc., it trains one massive model that learns about all language pairs at once. In order to avoid duplication, the model teaches itself about features that are common to families of languages, and features that are common to all written human languages. That way, even if it was not given enough examples from a particular language pair, it can extrapolate from examples in other related languages, and most likely get it right. It is called MoE (mixture of experts) because it incorporates specialized competing smaller models, called “experts”, each of which may propose an answer but each of which specializes in a type of problems, and it has another component that is trained to be good at determining which of the experts will be right under different circumstances.
Those engines went live in March 2022 and are available by invitation. They will probably be generally available some time next year. They are particularly good at languages for which there is a smaller training corpus, for example southern Slavic languages like Slovenian, Bosnian, and Bulgarian. If your language pair is among the ones that get a significant improvement in quality, it’s worth trying to get an invitation. At the moment, this can not be combined with Custom Translator.
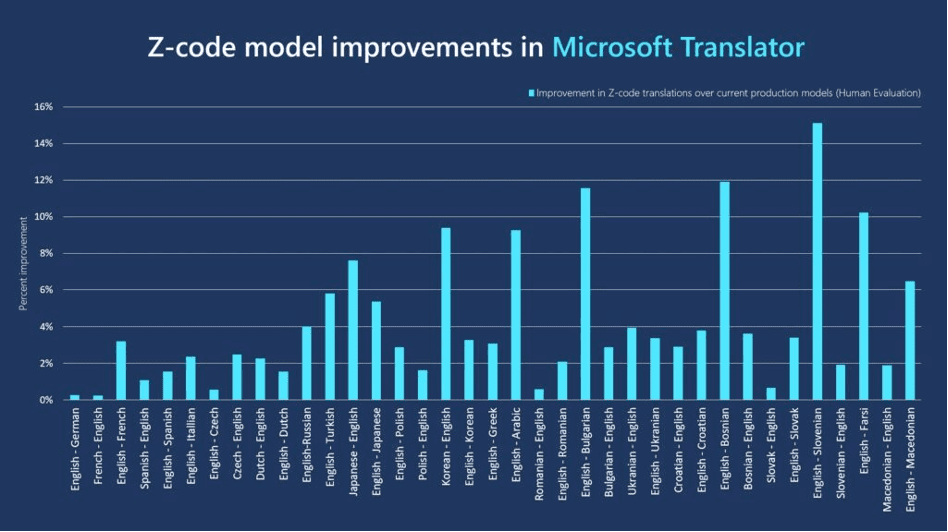
In the diagram above, the percent improvement seems to be improvement in BLEU score. According to other research, this class of models is particularly good for correcting negation errors in German. Note that 2) and 3) cannot be used together.
4. Write the original with a style that is easier to translate
This is a bit strange to say, but English is not a good source language to translate from. A lot of its grammar is vague or ambiguous. For example, it often recycles words to mean something else. Well known examples include “A good pharmacist dispenses with accuracy”. “Dispense” and “dispense with” are very different concepts that use the same words. It is obvious to humans from context, but how is a computer to know? “Bill gave the dog water and Sue the cat food”. Here the conjunction reuses the verb give, but the subject, direct object and indirect object require an educated guess. Is it a single object made up of one noun (cat) describing the other noun (food), or two different objects of the same verb? English does not have declensions and is stingy with the prepositions that other languages use to make such things clear. English is infamous for its sequences of nouns where the reader or computer must determine what describes what. For example, we can figure out “airport long term car park courtesy vehicle pickup point” from our knowledge of airports and car rentals, but can a computer figure out which word describes which other word or group of words enough to translate it? Machine translation would have more luck with the less common but still correct English phrasing “pickup point for the courtesy vehicles of the airport’s long-term car park”.
But before you decide to write all your original documents in Lithuanian rather than English to improve translation quality, know that it is possible to write in English in a way that is easier to translate.
Microsoft publishes some style guides with sections on how to author documents so that machine translation has fewer errors and is easier to understand. You can find them here.
Style guides for machine translation are similar to style guides for writing for ESL audiences, where some English language constructs that are potentially ambiguous for non-native speakers are avoided. Within the Microsoft style guides are some tips about writing so that machine translation will have higher quality.
https://docs.microsoft.com/en-us/style-guide/global-communications/writing-tips
Some of the tips seem to have been written at the time of earlier versions of machine translation which had problems that are less common now, but there is no harm in reducing ambiguity. The tips include:
- Use articles. Does “Empty container” mean “Empty the container” or “The empty container”? Articles (determiners) make it explicit.
- Reduce chains of modifiers. Instead of “well thought-out Windows migration project plan” say “a project plan to migrate Windows that's well thought out”
- Keep adjectives and adverbs close to the words they modify. Pay particular attention to the placement of “only”.
- ·Use simple sentence structures. Write sentences that use standard word order (that is, subject + verb + object) whenever possible.
- Use words ending in –ing carefully. A word ending in –ing can be a verb, an adjective, or a noun. Use the sentence structure and optional words to clarify the role of the –ing word.
- Use words ending in –ed carefully. A word ending in -ed can be a modifier or part of a verb phrase. Use the sentence structure and optional words to clarify the role of the –ed word.
- Add an article (a, an, the, this) before or after the –ed word. “They have an added functionality.”
- Add a form of the verb be. “Configure limits for the backup that are based on the amount of storage space available.”
I would probably add a few more tips. Be careful with the scoping of negation and of adjectives/adverbs (often a word can be one or the other). Keep the negation or the adjective close to what it modifies, whether a word, a noun phrase, a clause or the verb, and try to phrase it so it is not easily mistaken. An example of negation scoping is “All that glitters is not gold”. Is it saying that everything that glitters is made of something other than gold? It might, but it is probably asserting that the set of all items that glitter does not coincide with the set of gold items. It depends on whether it means {all that glitters} is-not gold, or {all that glitters} is not-gold. The “not” could be associated with “is” or with “gold”. I am tempted to wander into a digression into predicate logic or set theory, but that would take us away from the scoping problem. Not all who wander are lost 😉
Also be careful with words that can have several senses. Instead look for a different word with fewer senses.
Cultural differences
Cultural differences
Some translation issues are not easily solved with these strategies. This is because in addition to communicating across languages, you may be communicating across cultures.
There are translations that correct but are hard to understand or insensitive for cultural reasons. Some of them you can change before translation takes place, others can be caught during post-editing, but there is another alternative.
For example, if you talk about hitting a homerun, or about pulling the trigger, or call two things kissing cousins, these are cultural references that may be common in your country but may be hard to understand elsewhere even with a correct translation. More recent translation engines are better at common idioms, but it’s still risky. And it’s not just American English that draws from its culture. For example, Japanese has a term “mikka bouzu” meaning “three-day monk”. Some knowledge of Buddhism and Japanese culture is required to understand this is someone who gives up too easily. German has a word “Deppenleerzeichen” meaning “Idiot’s space”, a derogatory term for putting spaces between words that the German language normally sticks together in a large compound word. Some knowledge of German syntax is required.
Some more difficult cultural issues are better caught in post-editing. Some correct translations are to be avoided because they sound like slogans used by political parties or extremist groups. Catch me some day in person and I might tell you about some big yikes.
Another issue has to do with tone. A perfectly correct translation of communication written in German may sound inappropriate or even rude when translated to Japanese. That is because the German culture is comfortable with directness while Japanese employees are more comfortable with more indirect phrasing. Some re-training of the model using professionally translated text where the tone of business communication has been adjusted to be culturally appropriate is useful. However in some cultures such as Korean, verb forms and vocabulary depend on relative status of the writer and the reader, whether peer or subordinate, or on age difference. This is called honorifics or register. Similarly, many languages have differences based on the gender of the person being addressed or of the person who is speaking or writing. This is context that the computer does not have, so its phrasing may violate cultural norms.
When it comes to these cultural norms for things like tone, post-editing is the only way to fix these errors but correcting these type of errors can be time consuming, inconsistent with the “limited editing” that was recommended. Another alternative is to educate the readers of the translations about the cultural differences and explain that messages from that country may be expressed differently based on their different culture, and that no offense is intended. Educating the readers about cultural differences may be more cost effective than adapting all translations to the different cultural context.