Generative Pre-trained Transformer (GPT) systems are not designed to be translation engines. So it is surprising that they succeed so well at doing simple translations. Some articles have claimed that they can translate better than existing translation engines. How true are those claims?
Most of those claims are based on testing with a few sentences chosen by the author, few language pairs, and a qualitative scoring of how good the translation is. However, more systematic evaluations with large samples of more types of text, more languages, and more objective quality scoring by machines and humans tell a different story.
The best comprehensive evaluation was done by scientists at Microsoft Research, unsurprising because they are among the leaders in both machine translation and GPT models. The brief summary is that while GPT models have competitive quality when translating usual sentences from a major (see high-resource below) language to English, they are less good at other types of translation.
The evaluation uses three GPT systems that are known for translation quality, and compares them with neural machine translation engines (NMT), either Microsoft Azure API or the best-performing commercial systems or research prototype. Quality scoring uses either algorithmic scoring or human evaluation.
Languages and language direction
Languages and language direction
In most languages and for language directions, MS Azure Translator and other NMT engines outperform GPT for most measures of quality. However, GPT does have the ability to improve after being given a few examples of correct translations, and to outperform NMT in some language directions after 5 tries. This is the case for translations to English from German, Chinese and Japanese, languages for which there are a lot of examples in the GPT training set. These are called “high-resource” languages. On the other hand, it does not do particularly well for low-resource languages like Czech or Icelandic, or for English to other languages. GPT’s training set had less text in those languages. In the chart below, orange is GPT and blue is NMT. The lines are algorithmic evaluation and the bars are human evaluation.
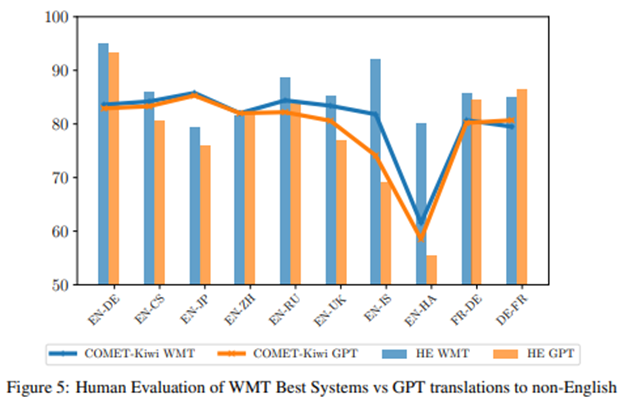
Sentence-level vs. multi-sentence
Sentence-level vs. multi-sentence
Those experiments above are for sentence-level translations. For multi-sentence translations, those with more context that can be found in other sentences, GPT improves relative to NMT. Not enough to beat the best NMT systems, but sometimes enough to match or beat the normal Azure API. That is not very surprising: Azure Translator was optimized for sentence-level translation, while GPT is trained for multi-sentence context, up to thousands of words. Other Azure translation APIs like Document Translator and Custom Translator are better at longer context windows, but this is not what was tested here.
Neural Machine Translation models have another big advantage over GPT: they can be re-trained for a particular domain rather than with general domains, and this significantly improves their quality score for that domain. For example, by giving it many training examples of automotive documents, Azure Custom Translator (a re-trainable version of Azure Translator) can increase its translation quality for documents in the automotive domain by a large factor.
Fluency and alignment
Fluency and alignment
Looking at other measures of performance gives a better understanding of what is different in the performance of the GPT vs. NMT. Measuring fluency, essentially how natural is the sentence, how similar it is to other sentences out in the world, tells you something about the quality of the prose. GPT is more fluent in English, it sounds more natural. That doesn’t mean that it is a more accurate translation, far from it. In fact, GPT has a greater tendency to add words, concepts, and punctuation that do not correspond to the original, or to omit some. So it’s good prose, but it’s not necessarily what the original said. For example, it does better at figures of speech, by not translating them literally, but also does not necessarily replace it with a term that means exactly the same thing. It does not wander far from the original with completely made-up things, but it’s often not quite correct. However GPT also does hallucinate words or concepts that were not in the original.

Translationese
Translationese
A literal and faithful translation is sometimes required, but that often leads to what is called “translationese”. This refers to a set of common issues with text generated by human translators. Translationese can refer to excessive precision or wordiness, or excessive vagueness in translated text, or syntax that is uncommon in the target language. What translators are compensating for is the fact that different languages are specific about different things. For example, English has the term “uncle”, which does not differentiate between paternal and maternal uncle or uncles by blood or marriage, but many other languages are much more specific. Translating from those other languages to English, Translationese would not say “uncle” but might say “maternal uncle by marriage”, a term that is unusual in English, but which avoids losing information that was contained in the original. In terms of translation quality, humans who are not translators might rate the translation with “uncle” higher because it sounds more natural, but translators would rate the awkward translation higher because it is more accurate.
Design and training of GPT and NMT
Design and training of GPT and NMT
There are big differences between the texts used to train GPT engines and the texts used to train NMT engines. GPT engines are trained on unilingual text found on the internet, mostly in English. For any sequence of words, GPT learns the most likely next word. NMT engines are trained on curated professionally translated sentences, pairs of original sentences and their translations. For all the curation, these data sets are often noisy and include incorrect translations that set back the training. For any sentence within a document in the source language, NMT predicts the translated sentence. This is part of the reason why NMT learns to produce translationese and GPT does not: it’s in the training set.
The design of the two types of models is also different. The “T” in GPT stands for “Transformer”. Transformer is an attention-based neural network model that when looking at a word within a sentence or even longer text, determines which other words are the most relevant ones to pay attention to. NMT also uses Transformer models. However, there are big differences. One is that GPT uses Decoder models, while NMT uses Encoder-decoder models. What does that mean? Decoder models focus on the output, the next word to be spit out. Encoder-decoder models try to extract features from the input before feeding it to the part of the model that predicts the output. It focuses separately on the input and on the output. It tries to be robust to small changes in the input.
GPT only outputs one word at a time. It starts with the text of the prompt plus other information in the input, then outputs a single word. Then it adds that word to the end of the prompt in the input and puts this new input through again to get the next word. It is unidirectional, that is to say when it is generating text it only looks at the previous words that are already generated, it doesn’t consider what it will say next because it hasn’t said it yet. Like a lot of humans, GPT is more concerned with what it wants to say next than with what you’re saying. NMT is bidirectional. It considers the rest of the sentence and the next sentence in both the source and the translation while it is generating the text. It generates entire sentences at once.
Because it is a generative model, GPT is biased towards what is usual. If the original text in the other language is commonplace and expected, then GPT will find good ways to express that text in English in ways that are commonplace and expected, because that is what it is trained to do. If the original says something that is unexpected or expresses it in unexpected ways, GPT’s translation is likely to replace it with something more usual using some of the same words. GPT does well at translation essentially because most things that require translation are predictable and unoriginal.
NMTs have a whole bag of tricks to deal with translation tasks that GPT does not, including specialized knowledge about the structure of languages, and tricks to deal with numbers, capitalization, and non-standard spacing correctly and efficiently. They are also trained to preserve information. You know that trick that people sometimes use, translating a sentence to another language then back to English so they can laugh at the result? NMTs include that round-trip in their training, to make sure that none of the meaning gets lost in the translation. Other tricks include having the neural network teach another neural network how to translate, detecting errors in the training data, and other tricks that address common translation errors. There are also tricks to reduce gender bias, a problem that still plagues GPT.
Computing power required
Computing power required
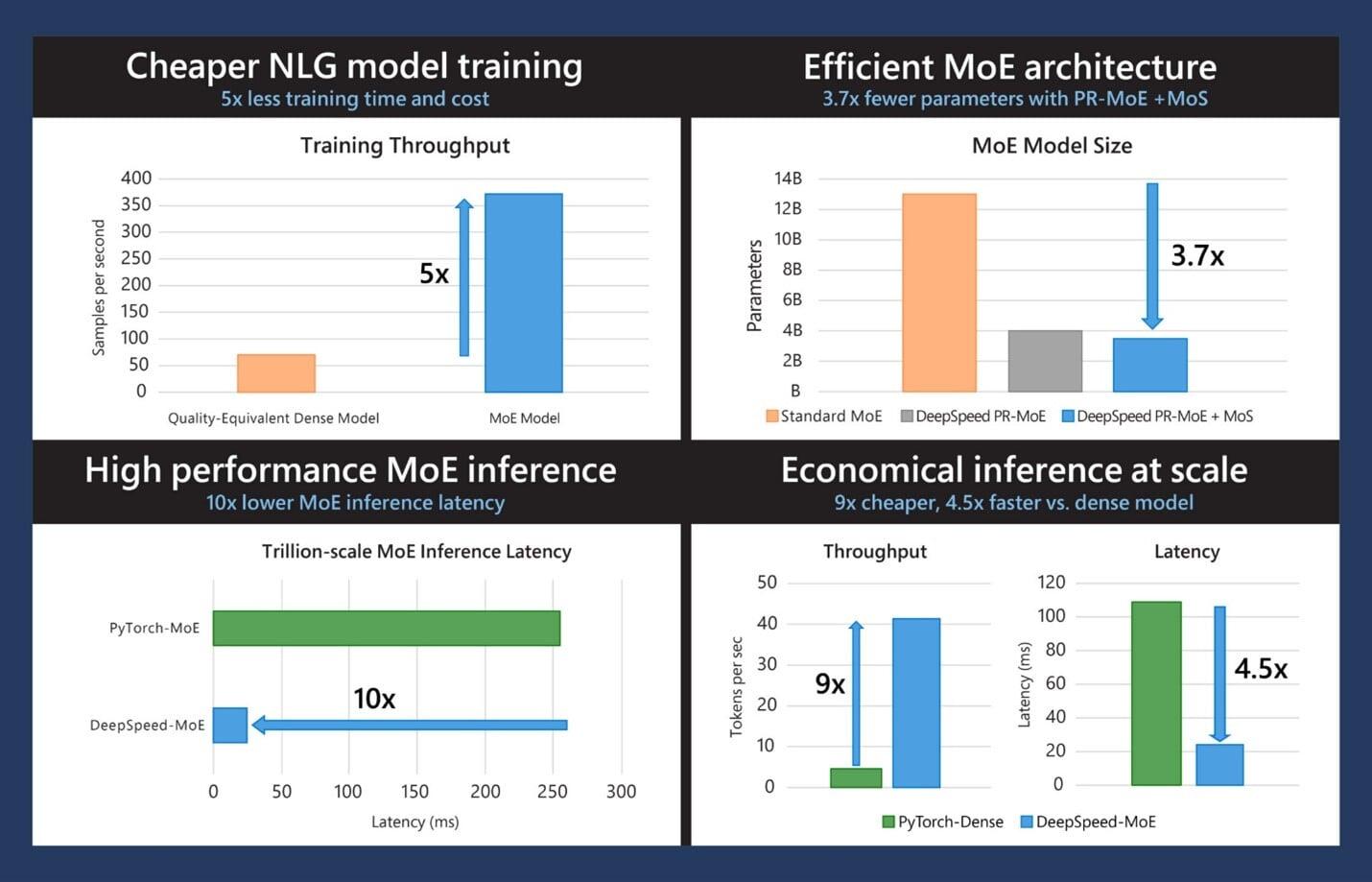
Current Azure Translator NMT uses models of about 50 million parameters, which can run 4 language pairs in a Docker container on a host having a 2-core CPU with 2 GB memory. Even the next generation of NMTs, Z-code MoE, which have 100 languages (10,000 language pairs) in a single model, can fit on a single GPU even though they have billions or hundreds of billions of parameters. These are sizes for querying, what is required for training is much bigger. GPT-4 uses 100 trillion parameters. Training requires hundreds of thousands of CPUs and tens of thousands of GPUs, but to query them, it looks like a single cluster of 8 GPUs and a dozen or two CPUs is what is required. Microsoft is very good at shrinking by orders of magnitude the size of machines required to run AI models so direct comparison is difficult, but NMTs deliver translations at much lower computational cost. Microsoft’s DeepSpeed library in particular increases speed and reduces latency by a large factor.
The computing power required also has a potential impact on security. NMTs, even the bigger potential NMTs can be run on a single processor, while GPT requires many processors. Using GPT you are probably sharing hardware with strangers, while for NMT it is possible to have dedicated resources. Because of its recurrent architecture, where the output is fed back into the input, GPT probably has some static storage of your data, while NMT can be architected with a pipeline where neither the input nor output text is ever stored. I don't know how it is implemented by anyone, but I notice that for Azure, NMT has a no-trace option by default while GPT limited access previews do not. Because of ethical concerns, data is probably retained for abuse monitoring. I'm sure the security is good, but the architecture reduces the options for security.
Conclusion
The blanket claim that GPT is better at translation in not generally true. However GPT is surprisingly good, considering that translation is a task that it was neither designed nor trained for. It is unexpected that it is sometimes equal to or better than the highly specialized NMTs. There is a fair bit of work being done on hybrid systems that combine the accuracy and specialized training of NMT with the fluency of GPT and will deliver the best of both. The next generation of NMT (see How to get a higher level of machine translation quality) will also allow the model to transfer language knowledge obtained from one language to other related languages, and in that way vastly improve the quality for low-resource languages such as southern Slavic languages. That innate knowledge of what is common to languages in the same family can then be used to improve the quality of both NMT and GPT.